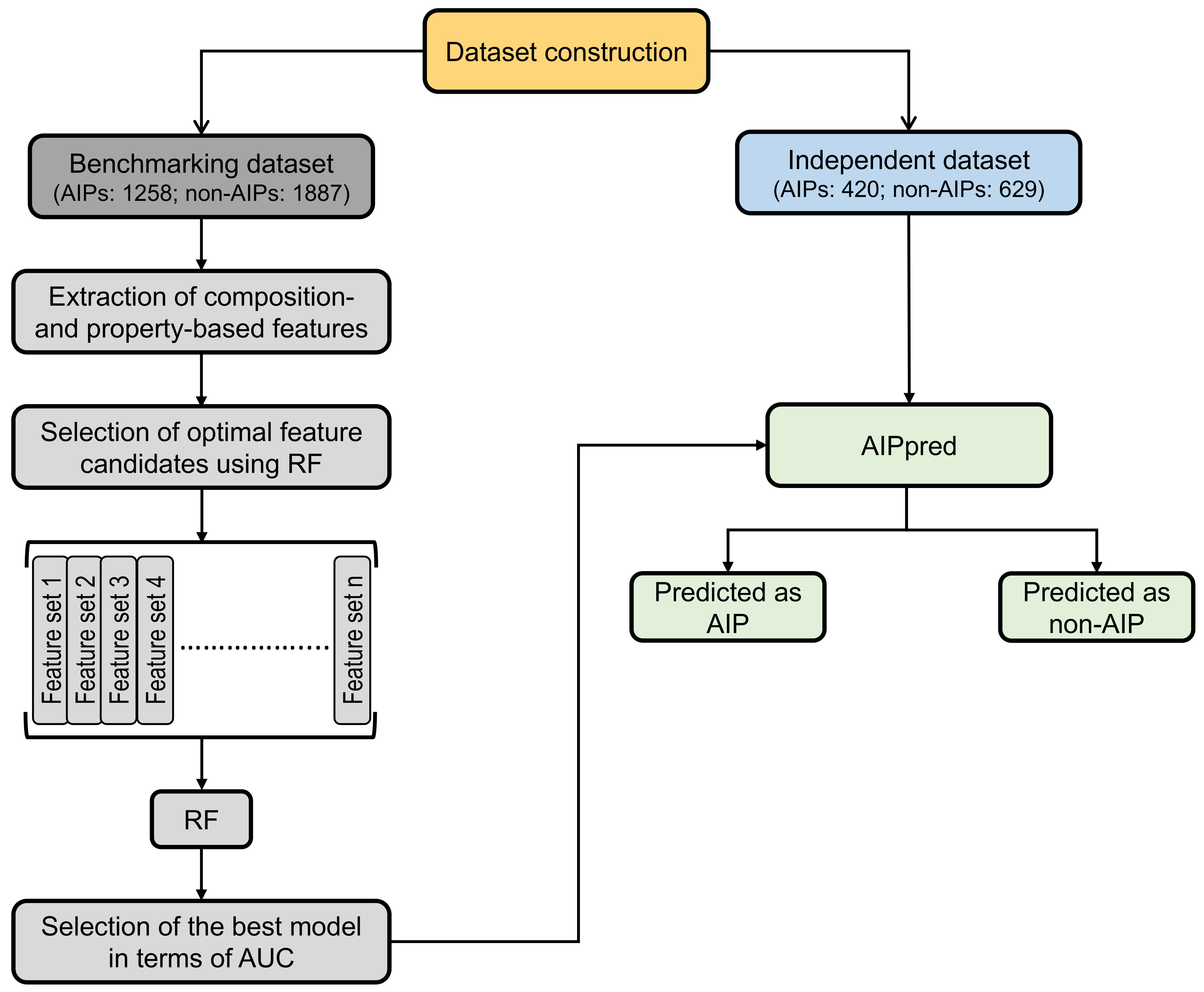
Development of SVM-PVP consisted of four steps: (i) construction of the benchmarking and independent datasets; (ii) extraction of various features from the primary sequences, including amino acid composition, atomic composition, chain-transition-composition, dipeptide composition, and physicochemical properties; (iii) systematic evaluation of individual composition and generation of 35 different feature sets based on feature importance scores (FIS) computed using the RF algorithm. These different sets were inputted to the RF to develop their respective prediction models; and (iv) the model producing the best performance in terms of AUC was considered the final model, and the corresponding feature set was considered the optimal feature set.
Reference
AIPpred: sequence-based prediction of anti-inflammatory peptides using random forest (Frontiers in Pharmacology). [Please cite this paper if you find AIPpred useful in your research]